Thursday
Aug162018
v2.0.0-beta released!
If you like things which aren't yet done but can still be useful in some respects, grab it on github!

If you like things which aren't yet done but can still be useful in some respects, grab it on github!
It's time for benchmarks!
Historically, performance improvements in BEPUphysics v1 came incrementally. Each new big version came with a 20% boost here, another 10% over there, gradually accumulating to make v1.5.1 pretty speedy.
The jump from v1.5.1 to v2.0.0, even in its alpha state, is not incremental.
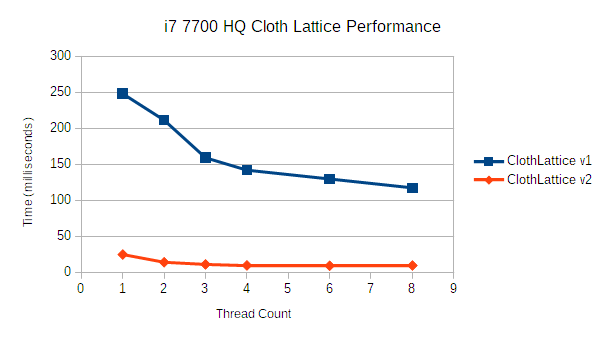
That's a change from about 120 ms per frame in v1 to around 9.5 ms in v2 when using 8 threads. The difference is large enough that the graph gets a little difficult to interpret, so the remaining graphs in this post will just show the speedup factor from v1 to v2.
If you'd like to run the benchmarks yourself, grab the benchmarks source from github: github.com/RossNordby/scratchpad/tree/master/Benchmarks
I bugged a bunch of people with different processors to run the benchmarks. Some of these benchmarks were recorded with minor background tasks, so it's a fairly real world sample. All benchmarks ran on Windows 10 with .NET Core 2.0.6.
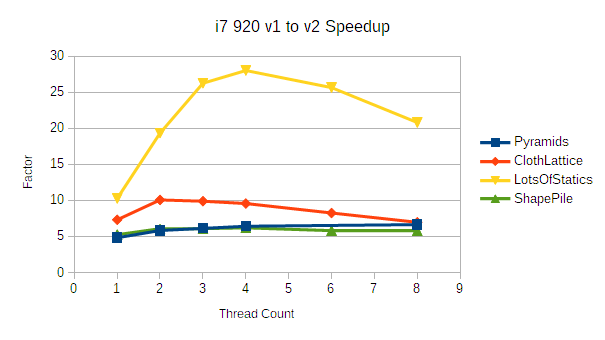
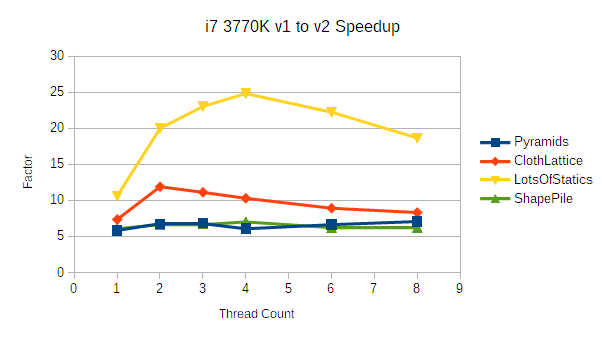
ShapePile and Pyramids both require quite a bit of narrow phase work which involves a chunk of scalar bookkeeping. With fewer opportunities for vectorization, they don't benefit as much as the extremely solver heavy ClothLattice benchmark.
Note that the ClothLattice benchmark tends to allow v1 to catch up a little bit at higher core counts. This is largely because of limited memory bandwidth. The solver is completely vectorized apart from the bare minimum of gathers and scatters, so it's difficult to fetch constraints from memory as quickly as the cores can complete the ALU work. v1, in contrast, was just a giant mess of cache misses, and it's very easy for cores to idle in parallel.
LotsOfStatics is another interesting case: statics and inactive bodies are placed into an extremely low cost state compared to v1. In fact, the only stage that is aware of those objects at all is the broad phase, and the broad phase has a dedicated structure for inactive bodies and statics. In terms of absolute performance, the LotsOfStatics benchmark took under 350 microseconds per frame with 8 threads on the 3770K.
Notably, this is an area where v2 still has room for improvement. The broad phase is far too aggressive about refining the static structure; I just haven't gotten around to improving the way it schedules refinements yet. This particular benchmark could improve by another factor of 2-4 easily.
Now for a few AVX2-capable processors:
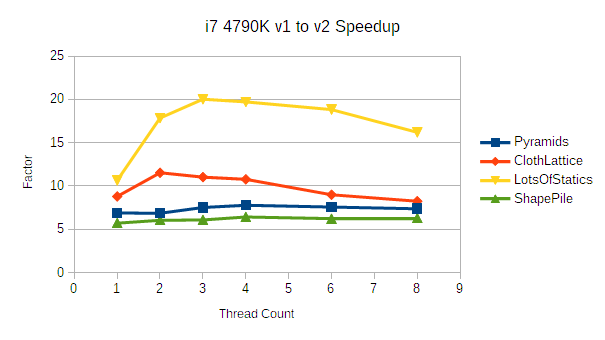
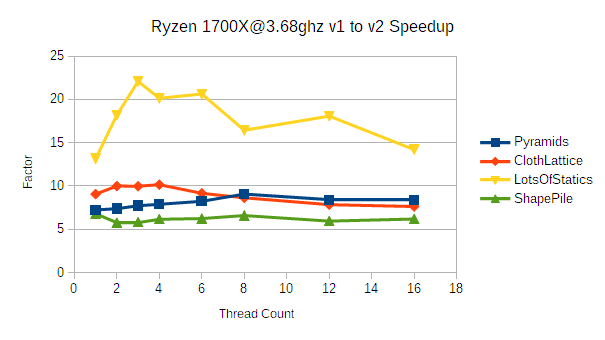
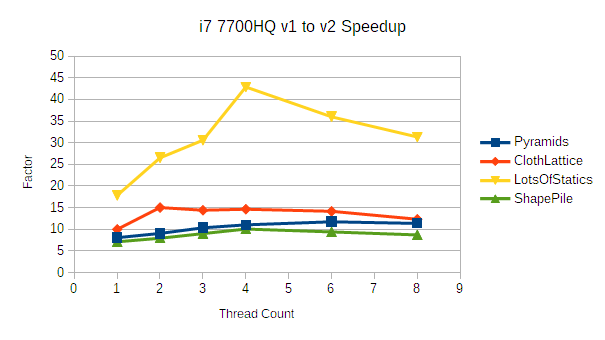
There are some pretty interesting things going on here. Most noticeably, the 7700HQ shows a much larger improvement across the board than any of the other processors tested. This is expected when comparing against the 128-wide platforms (3770K and 920) thanks to the significantly higher floating point throughput. The ClothLattice demo in particular shows a speedup of 10-15x compared to the 3770K's 7.4-11.9x.
While I haven't verified this with direct measurement, I suspect the 7700HQ benefits more than the AVX2 capable 4790K and 1700X thanks to its significantly higher effective memory bandwidth per core. The 4790K roughly matches the non-AVX2 3770K in bandwidth, and 1700X actually has significantly less bandwidth per core than the 3770K. The memory bandwidth hungry ClothLattice benchmark timings are consistent with this explanation- both the 4790K and 1700X show noticeably less benefit with higher core counts compared to the 7700HQ.
Zen's AVX2 implementation also has slightly different performance characteristics. I have not done enough testing to know how much this matters. If RyuJIT is generating a bunch of FMA instructions that I've missed, that could contribute to the 7700HQ's larger improvement.
There also a peculiar massive improvement in the LotsOfStatics demo, topping out at 42.9x faster on the 7700HQ. That's not something I expected to see- that benchmark spends most of its time in weakly vectorized broadphase refinements. I haven't yet done a deep dive on refinement performance (it's slated to be reworked anyway), but this could be another area where the 7700HQ's greater bandwidth is helpful.
v2 is vastly faster than v1. It's not just a way to save money on server hardware or to allow for a few more bits of cosmetic debris- it's so much faster that it can be used to make something qualitatively different.
And it's going to get faster!
v2 hasn't yet learned many tricks, but it's growing up fast. I took it out of its crib and gave it its own bed:
I'm putting a little more effort into public issue tracking to make it easier to see ongoing progress.
Hopefully not that much longer yet before the library is actually useful!
I decided to move the demos over to monogame after many years of procrastination, then looked back on all the commits and said, hey, I might as well package these up for a release.
Then codeplex was temporarily refusing my pushes, so I said, hey, might as well put it on github.
Check out the newness on github!
(Certain observers may note that BEPUphysics v2 is, in fact, not yet out, nor is it even being actively developed yet. Don't worry, it's not dead or anything, I just have to get this other semirelated project out of the way. I'm hoping to get properly started on v2 in very early 2017, but do remember how good I am at estimating timelines.)
 BEPU
BEPU